Potrzebuję oprogramowania, aby wyodrębnić konkretne strony z moich obszernych plików PDF, nie obniżając jakości oryginalnego pliku.
Rozwiązuje Narzędzie do Ekstrakcji Stron PDF
Problem
Formułowanie problemu odnosi się do konieczności wyodrębniania specyficznych stron z obszernych plików PDF. Zarówno w kontekście studenckim, podczas zbierania materiałów badawczych, jak i w profesjonalnym, podczas kompilowania raportów - możliwość selektywnego pobierania informacji z PDF-ów ma wielkie znaczenie. Dlatego szukamy efektywnego, przyjaznego użytkownikowi narzędzia oprogramowania, które może poradzić sobie z tym zadaniem. Jest to ważne, aby jakość oryginalnego pliku nie była naruszona. Powinno więc znaleźć się rozwiązanie, które umożliwia dokładny dobór i ekstrakcję stron PDF, bez narażania integralności oryginalnych dokumentów.
Zrzuty ekranu
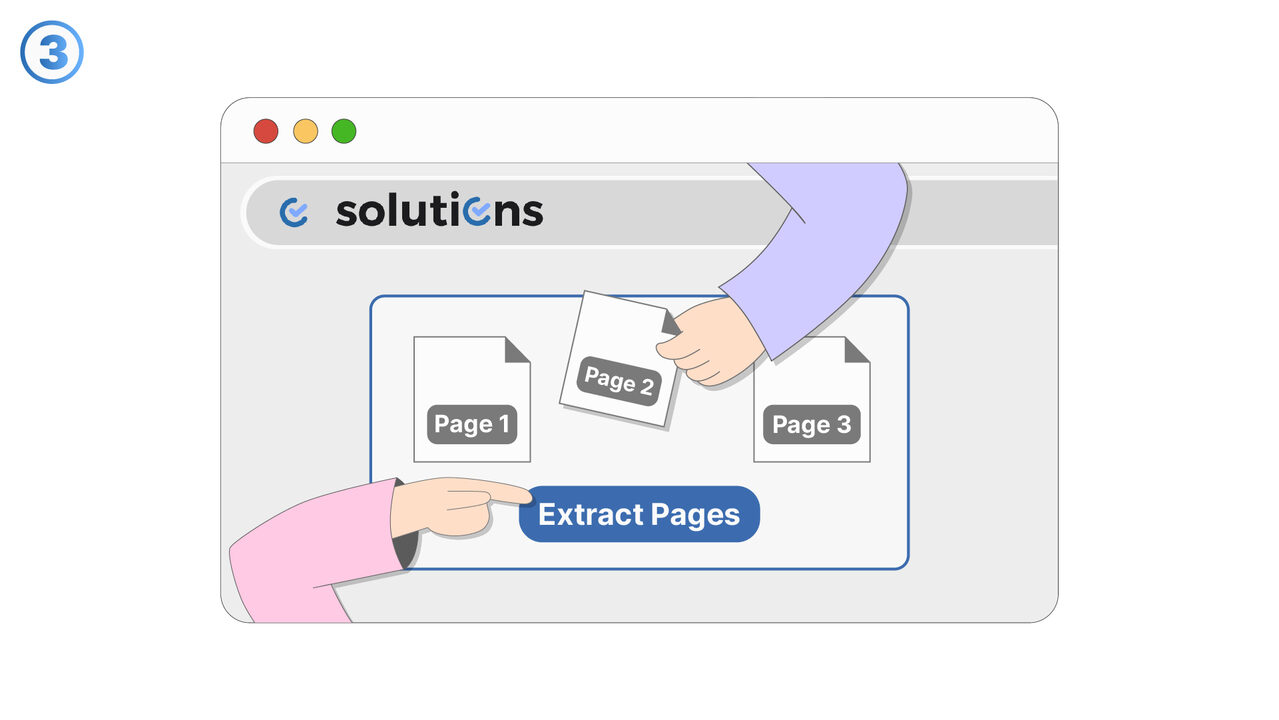
Wypróbuj
Rozwiązanie
Narzędzie do ekstrakcji stron z plików PDF oferuje optymalne rozwiązanie dla zarysowanego problemu. Dzięki przyjaznemu dla użytkownika interfejsowi, użytkownicy mogą celowo wybierać żądane strony i ekstrahować je z całościowego pliku PDF. Jakość oryginalnego dokumentu pozostaje przy tym w pełni zachowana. Zarówno dla studentów, jak i pracowników, jest to proste i efektywne narzędzie do izolowania istotnych informacji z obszernych plików PDF. Korzystanie z narzędzia umożliwia precyzyjne i szybkie zbieranie informacji, co jest gwarantowane dzięki jego nacisku na przyjazność dla użytkownika i efektywność. Ponadto, korzystając z narzędzia, integralność oryginalnych dokumentów pozostaje nietknięta. W ten sposób oferuje ono doskonałe i bezpieczne rozwiązanie do ekstrakcji stron z plików PDF.
Zewnętrzny zasób
https://tools.pdf24.org/en/extract-pdf-pages
Użyj tego narzędzia jako rozwiązania następujących problemów
- Mam problemy z wyodrębnianiem konkretnych stron z pliku PDF.
- Podczas wyodrębniania poszczególnych stron z mojego pliku PDF obawiam się, że mogę stracić dane.
- Mam problemy z przetwarzaniem bardzo dużych plików PDF za pomocą mojego aktualnego narzędzia do ekstrakcji.
- Mam problemy z czasem potrzebnym na ekstrakcję pojedynczych stron z moich plików PDF.
- Mam trudności z wyodrębnieniem konkretnych stron z mojego obszernego pliku PDF.
- Potrzebuję sposobu na wyodrębnienie konkretnych stron z moich plików PDF, bez utraty jakości oryginalnego pliku.
- Mam problemy z rozpoczęciem korzystania z narzędzia do ekstrakcji stron PDF.
- Mam problem z wyodrębnieniem konkretnych stron z mojego pliku PDF, bez powodowania niechcianych zmian w oryginalnym pliku.
- Mam problemy z pobieraniem i udostępnianiem wyodrębnionych stron z mojego PDF.
Znasz lepsze rozwiązanie? Daj nam znać.
Jeśli znasz narzędzie lub podejście, które mogłoby pomóc rozwiązać problem, którego jeszcze nie omówiliśmy, chętnie się o tym dowiemy.