När jag extraherar enskilda sidor från min PDF-fil, är jag orolig för att förlora data.
Problemet
Den exakta problemformuleringen som användare ställs inför är rädslan för att förlora värdefulla data när man extraherar utvalda sidor från en komplex PDF-fil. Dessutom finns det bekymmer att kvaliteten på originaldokumentet kommer att påverkas. Bekymren inkluderar också risken att viktiga områden eller innehåll i filen oavsiktligt kan ändras eller raderas när sidor tas ut. I vissa fall behöver användare specifika sidor från deras PDF-filer för separata ändamål, men rädslan för dataförlust hindrar dem från att utföra denna uppgift. Kort sagt, bekymmerna handlar om säkerhet och integritet av den ursprungliga PDF-filen vid utdragning av enskilda sidor.
Skärmbilder
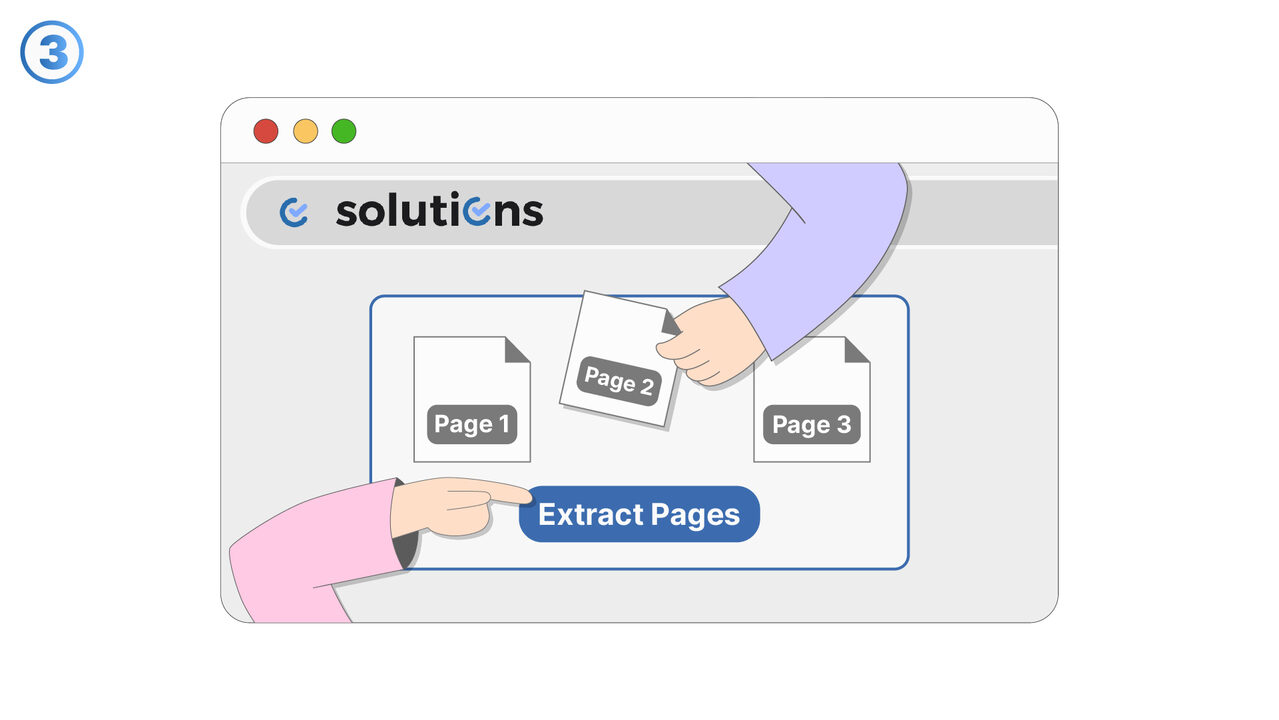
Prova det
Lösningen
Sidextraktorn för PDF-filer har speciella funktioner som ger omfattande skydd mot dataförlust. Med sitt intuitiva användargränssnitt kan användare enkelt välja och extrahera specifika sidor utan att ändra originalfilen, vilket eliminerar oron för oavsiktlig radering eller ändring av innehåll. Kvaliteten på originalet förblir även opåverkad, eftersom verktyget endast skapar en kopia av de valda sidorna och lämnar den ursprungliga filen oförändrad. Processen är snabb, noggrann och innebär ingen dataförlust, så att enskilda sidor kan extraheras säkert och utan att skapa duplikat. Således kan användare extrahera specifika sidor för vidare användning utan att riskera den ursprungliga PDF-filen. Sammanfattningsvis ger PDF-sidextraktionsverktyget användarna en bekymmersfri möjlighet att extrahera sidor från deras PDF: er samtidigt som integritet och kvalitet på originalet bibehålls.
Extern resurs
https://tools.pdf24.org/en/extract-pdf-pages
Använd det här verktyget som en lösning på följande problem
- Jag har problem med att extrahera specifika sidor från en PDF-fil.
- Jag har problem med att bearbeta mycket stora PDF-filer med mitt nuvarande extraktionsverktyg.
- Jag behöver en programvara för att extrahera specifika sidor från mina omfattande PDF-filer utan att påverka kvaliteten på originalfilen.
- Jag har problem med tidsåtgången för att extrahera enskilda sidor från mina PDF-filer.
- Jag har svårigheter att extrahera specifika sidor från min omfattande PDF-fil.
- Jag behöver ett sätt att extrahera specifika sidor från mina PDF-filer utan att förlora kvaliteten på den ursprungliga filen.
- Jag har problem med att komma igång med att använda verktyget för att extrahera sidor från PDF-filer.
- Jag har problem med att extrahera specifika sidor från min PDF-fil utan att orsaka oönskade ändringar i originalfilen.
- Jag har problem med att ladda ner och dela extraherade sidor från min PDF.
Känner du till en bättre lösning? Låt oss veta.
Om du känner till ett verktyg eller ett tillvägagångssätt som kan hjälpa människor att lösa ett problem vi ännu inte täckt, hör vi gärna det.